


We’ve all heard the term Continuous Delivery thrown around. We usually find it coupled with terms like DevOps and immutable infrastructure. Simple examples of continuous delivery are not hard to come by, but after reading through them you may find yourself with more questions than answers when trying to apply the techniques to complex, real-world applications. In this article we’ll look at some advanced use cases for continuous delivery as well as some best practices to make it run smoothly.
Defining Continuous Delivery
Before we begin exploring advanced continuous delivery scenarios, we should first take the time to define continuous delivery and establish a few best practices. It’s very difficult to go from zero to continuous delivery in one shot. It’s much easier and more effective to take a phased approach. The phases are:
- Deployment
- Automated Deployment
- Continuous Delivery.
Let’s look at each one of these phases.
Phase 1: Deployment
This first step involves defining what a deployment of your system looks like. What pieces need to be built and deployed? Do you have a database? API servers? Front end web? Are you deploying a backend and a mobile app? You must start by defining your deployable artifacts. These are the packages that you need to build or assemble for a deployment. Once you have defined your artifacts you can setup a build server and build process to create the artifacts as needed.
Phase 2: Automated Deployment
Now that you have defined your build artifacts and setup a build server to create them, it’s time to start automating parts of your deployment. Don’t over think this step, it can be as simple as writing bash scripts to grab your artifacts and move them to the target environment. As you build out scripts and tools to handle your deployment for you, you will want to look at tokenizing these scripts so that they can accept arguments for the versions of your build artifacts and the environment they will deploy to. This will aid in creating a process that can be deployed continuously. It’s also a good idea to keep these scripts in source control along side the code they are deploying. This allows the scripts to be naturally versioned in sync with the code so that they evolve together over time. This is important because if you ever need to deploy an older revision of your system, the deployment scripts will still match the state of the system they were designed to deploy.
Phase 3: Continuous Delivery
Now that you have automated the steps of your deployment, it’s time to make this happen without direct intervention. A continuous delivery system is comprised of triggers that will kick off the build and deploy process based on events that happen in your development and testing process. Begin by defining when a build should occur. On each check-in to the master branch? Maybe each feature branch check-in? Next define triggers for deploying your artifacts automatically. Choose triggers that align with the business goals of your deployment. You might want each check-in to a feature branch to deploy to a demo environment for show and tell at your sprint close out meeting. When a build occurs on the master branch you may want to deploy that to the staging area for testing before sending it to production. Since we tokenized our deployment scripts we can easily setup a system that will deploy to a testing and demo environment when check-ins occur on a feature branch and send builds from the master branch into the production environment.
Best Practice: Semantic Versioning
We tend to think of versioning as something that is only important for systems that are published for outside consumption (like the public API for Twitter); however, versioning for internal systems is critical to a successful continuous delivery system. By following the semantic versioning system, we can make automated decisions about which versions of our components can be deployed together. For example, when building and deploying a micro-services architecture, each micro-service is expected to fulfill a contract to the rest of the system. If a service introduces a breaking change, we can prevent it from being deployed until the systems that depend on it have been updated. Versioning is especially helpful in internal libraries and APIs that are consumed by other pieces of our system. Maintaining proper semantic versions allows us to setup advanced continuous delivery scenarios such as the Zero Downtime deployment strategy and the Stable Schema deployment strategy outlined below.
Continuous Delivery Scenarios
Zero Downtime Deployment Strategy
In this scenario we will examine how to achieve a phased rollout of our deployment with no downtime for our users. This scenario is based on the following n-tier architecture Fig 1:
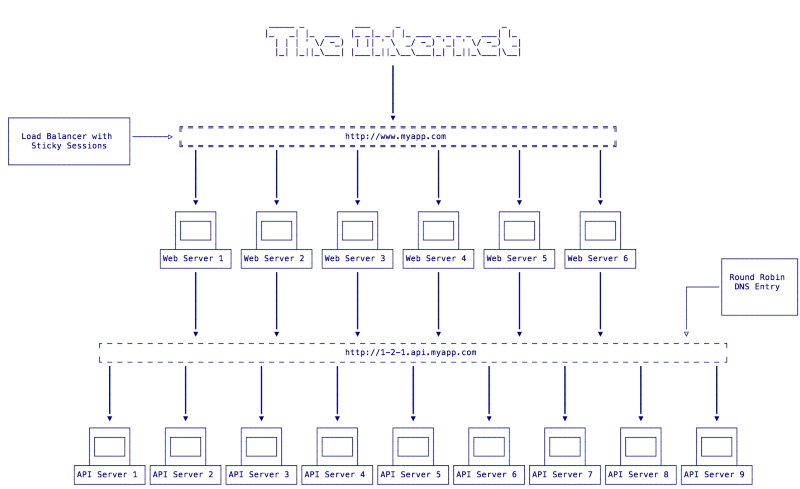
In this architecture we have a web application that is served at http://www.myapp.com by a farm of 6 web servers behind a load balancer. The load balancer is configured for sticky sessions so that requests from a given client will continue to be sent to the same web server as long as it is available. The web servers make requests to the API servers via a round-robin DNS entry that includes the version (v 1.2.1) of the app at 1–2–1.api.myapp.com.
When we are ready to deploy version 1.3.o of our app we will pull API servers 6–9 out of the round-robin DNS entry for 1–2–1.api.myapp.com and move them to a new entry at 1–3–0.api.myapp.com. This will leave our system in the state seen in Fig 2:
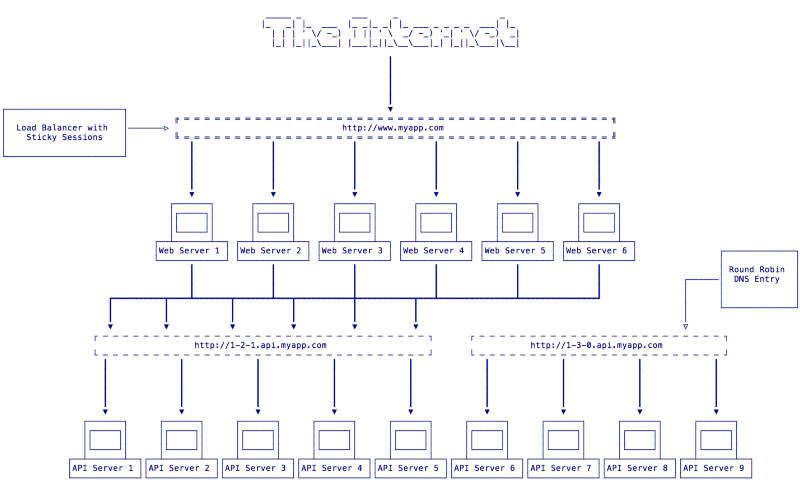
As you see in Fig 2 all web servers are still sending requests to v1.2.1 of our API so users can continue to use our app. Now we can upgrade API servers 6–9 to v1.3.0. Once this is complete we need to deploy v1.3.0 of our frontend application to talk to the new API servers. We will drain the connections from web servers 4–6 so that all frontend traffic will be directed to web servers 1–3. Now we can deploy v1.3.0 of our front end app which is configured to make API calls using the v1.3.0 url of 1–3–0.api.myapp.com. This will leave our system in the state seen in Fig 3:
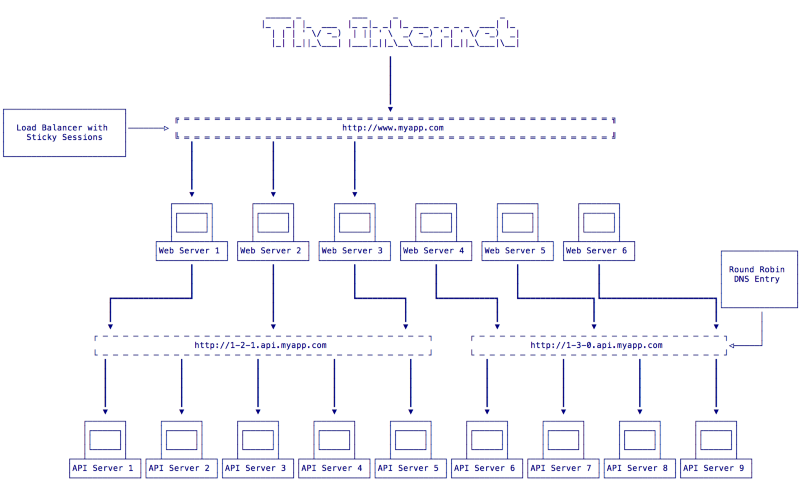
Now we have a full stack of servers that are ready to serve v1.3.0 of our application. At this point it would be wise to have some automated smoke tests built into your continuous delivery pipeline to test the servers running v1.3.0 and make sure they are ready to serve public traffic. If everything passes we can bring those servers back into the load balancer to let a portion of our users start using the new version of the app. Now our system will be in the state seen in Fig 4:
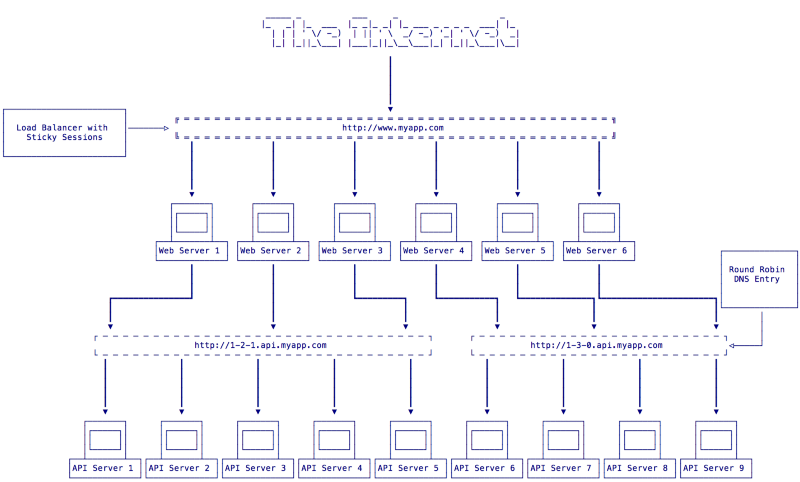
Remember that our load balancer is configured for sticky sessions so users who connect to a v1.2.1 web server will continue to get that version of the app while other users will connect to v1.3.0 servers. You don’t have to do this with half of your infrastructure all at once, you may want to do a smaller portion such as 10%. This allows you to pause your rollout and see how the app performs with real users in the system. If everything looks good you can continue applying this strategy until your entire infrastructure has the new v1.3.0 of the app deployed.
Stable Schema Deployment Strategy
Another spot where versioning really helps with continuous delivery is managing your database schema across deployments. While an application deployment is generally immutable, your database has something valuable in it: all your data. This means that making changes to your schema requires a little more planning and having a good strategy in place to deal with schema changes.
Let’s say we have built v1.0.0 of our application and we decided that we want to track what each one of our users’ favorite color is. We create a schema and API to support this as seen in Fig 5:
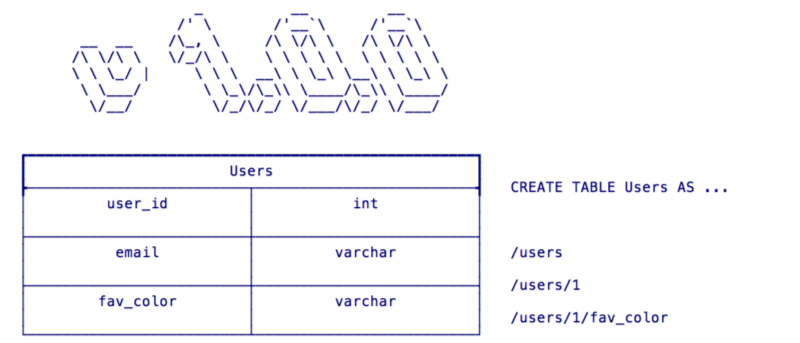
Great! Now we’re tracking our users’ favorite colors. But then our startup pivots to disrupt a new space with better network effects and as a result we no longer care about tracking a user’s favorite color. So for v2.0.0 of our hot new app we remove the /users/{id}/fav_color endpoint and we’d like to get rid of that, now unneeded, column from our table. But remember our Zero Downtime Deployment Strategy? We’re going to have both v1.0.0 and v2.0.0 of our app running side by side for a period of time. Therefore, we don’t want to just drop that column. So we deploy a schema for v2.0.0 that looks like Fig 6:
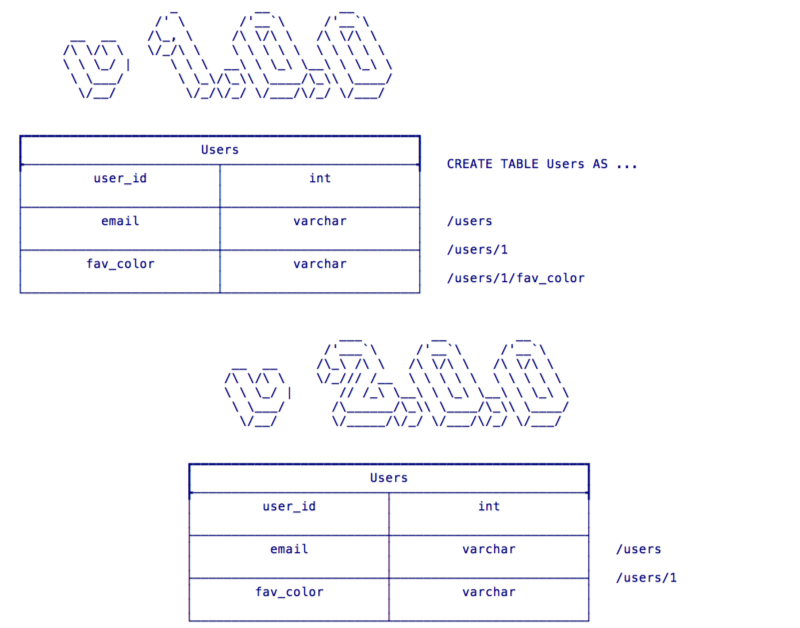
Now we can happily serve both v1.0.0 and v2.0.0 of our application. Once we have fully deployed v2.o.0 and completely retired v1.0.0 we are free to remove the unneeded column in a future update as in Fig 7:
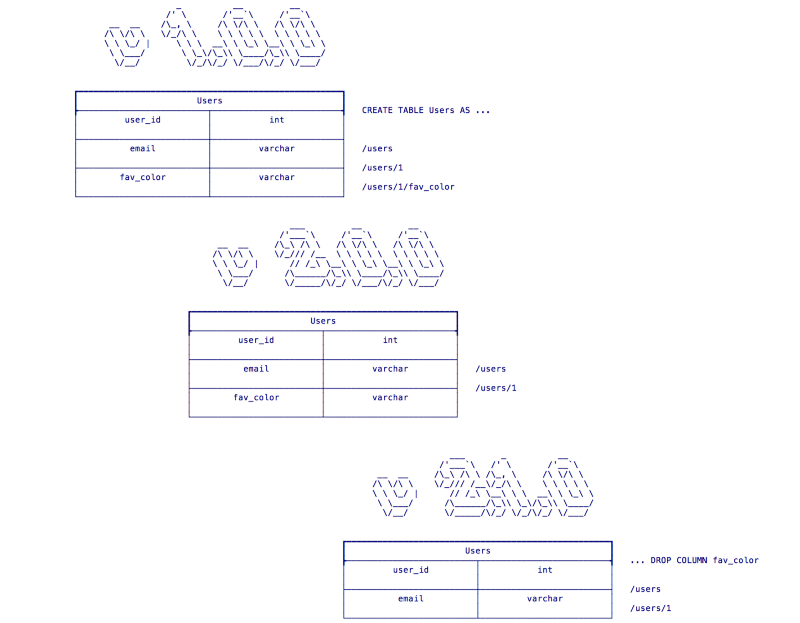
This principal extends beyond simply dropping columns. For example, if we need to change a datatype for a column we might want to instead add a new column that copies the data from our existing column on deployment and write our new code against the new column. Then once we have fully deployed the new code we are free to drop the old column. This is obviously an oversimplification, but it illustrates how a little advanced planning and properly applied versioning goes a long way when evolving a database schema over the life of an app.
Conclusion
In this article we have defined what it takes to plan out a continuous delivery system and explored some best practices to make sure our system is successful. As you look to plan out your application’s continuous delivery pipeline, remember to iterate on your process and be sure to apply good semantic versioning along the way.
Originally published at blog.codeship.com on November 25, 2015.